
客服电话: 400-999-3607

web如同一个大型的大数据库,其中包含各种各样有价值的信息,当您需要把某些特定信息采集下来,却往往可能面临这样的困境:
集搜客GooSeeker与“技术小白”共同成长。秉承此宗旨,集搜客GooSeeker抓取软件操作简单,完全可视化操作,无需编程基础,熟悉电脑操作即可轻松掌握:
整个采集过程所见即所得,遍历的链接信息、抓取结果信息、错误信息等都会及时地反映在软件界面中。让您整个操作清晰明了,带着轻松的心情完成自己的任务。
集搜客GooSeeker的模板资源套用特性,让您轻松快捷地获得数据。
在集搜客资源库中,分门别类存放着抓取规则,既可通过关键词也可通过目标网页网址搜索到可用的抓取规则。在抓取规则的详情页面,您可以仔细考察一个规则的抓取结果是否满足您的需要,如果满足,只需点击“下载”按钮,即可在会员中心一键启动集搜客网络爬虫,抓取到你想要的数据。比如:
省却自己定义抓取规则的麻烦,像直接套用网页模板一样使用发布出来的规则。对于初学者或者业务目标导向的用户,模板资源套用是一条捷径。
集搜客GooSeeker网络爬虫与其它网络爬虫相比,在易用性方面已经远远胜出,加上 一键启动网络爬虫这个独特性功能和整个[资源共享平台]的支撑,已经大大降低了对用户的技术基础条件的要求。然而,网页抓取毕竟是一个技术工作,需要适当掌握HTML等基础知识。也就是说需要花费一些时间学习这个软件的使用方法。既然已经有所投入(即便是时间上的),那么网络爬虫的通用性高低显得十分重要。
集搜客网络爬虫历经8年行业历练,采用功能强大的火狐浏览器内核,所见即所得。很多动态内容并不在HTML文档中出现,而是动态加载,都不影响精确抓取他们,而且不用网络嗅探器从底层分析网络通信消息,与抓取静态网页一样可视化定义抓取规则。再加上开发者接口,能够模拟十分复杂的鼠标和键盘动作,一边动作一边抓取。
抓取范围可以归纳成如下几类:
可见,使用集搜客网络爬虫,整个互联网成为你的数据库!
这是爬虫群并行抓取的一种特殊情形,利用这个功能,您可以低成本快速汇集海量数据。场景描述如下:
那么,您可以创建一个工作组,并邀请网友加入,为了得到更多会员的响应,您可以发“红包”,接受任务的社友就会用他的的电脑帮你分担采集数据。 在社区中别人会帮你采集数据,当然你也可以帮助社友抓取数据,赚取更多的积分,后面有任务时再把积分悬赏发给社友。
使用过程中要注意:
从网站上采集数据,尤其采集大型网站时,被采集的数据往往位于网站的不同层级的网页上,大大增加了网络爬虫采集数据的难度。百度或者google这样的综合网络爬虫,能够自动管理爬行的深度和广度。我们这里讨论的是聚焦网络爬虫,希望能够以尽量低的成本获得数据,而且希望只获取需要的网页内容。所谓聚焦,主要包含两方面:
集搜客GooSeeker就是这样的聚焦网络爬虫,但是跟其他市面上的采集器不同:
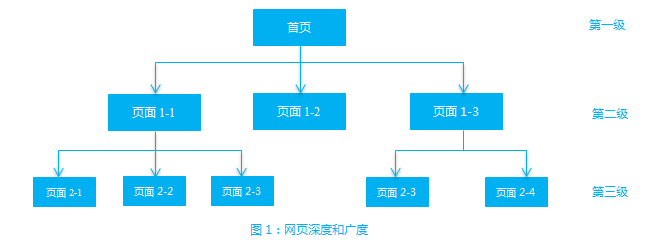
在网站的信息架构中,有一种组织结构叫做树形结构:网站首页视为链接层级中第一级,与其有从属关系的页面视为链接层级中的第二级,一般称其为二级页面。通过二级页面又可以继续得到第三级页面,依此类推可以得到一个完整的树形链接结构。这样一个完整的链接结构,如图1所示。
在整个树形结构中,链接的层数被称为网页链接的【深度】(depth)。而在树形结构里,每层页面包含的页面总数被称为网页链接的【广度】(breadth)[1]。因此,图1中树形结构深度3,树形结构第三层的广度为5.
进入大数据时代,互联网不再局限于发布文字内容和提供关键词搜索。越来越多的数据经过统计、分析、挖掘,并用可视化图表展示出来,比如,
还有众多垂直领域的指数图表网站,他们对数据进行深度挖掘加工以后展示出来。那么从网页上抓取数据不再局限于文本内容,如果能够直接从图表上抓取数字将有更大价值,原因如下:
集搜客网络爬虫具有强大的图表数据抓取能力,而且提供一个开发者扩展接口,允许技术基础高的用户用Javascript自定义更高级的网络爬虫动作,比如
总之,集搜客GooSeeker网络爬虫不仅能抓取文本数据、图片、表格,还能模拟鼠标动作,抓取在指数图表上悬浮显示的数据,无论是新闻资讯图表、电商网站上的产品介绍图片、电商经营分析数据还是指数走势图,只要使用集搜客软件就能抓取到完整的图表信息,让整个互联网成为您的数据资源库。
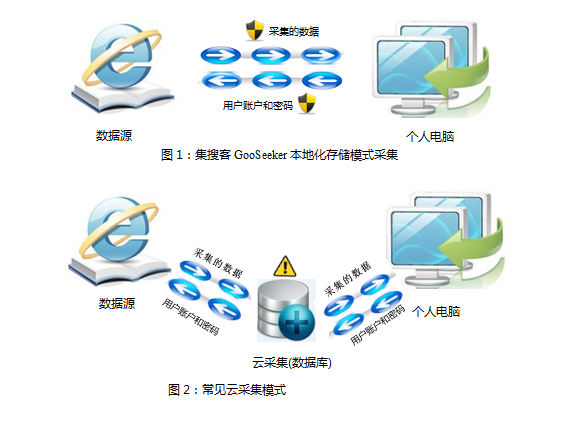
在互联网时代,用户的隐私安全越来越受到人们重视,而集搜客GooSeeker的本地化存储机制,能充分保护用户隐私安全。体现在多方面:
相反,如图2所示,其他云采集方案要求用户必须把账号和密码先存储在大家都共享的云数据库,让云端的网络爬虫自动登录后执行采集,大大增加用户账户泄露的可能性,同时,云采集数据必需经过云服务器再到用户个人电脑,增加用户采集行为和结果数据被暴露的可能。
在采集网站数据的时候,需要输入验证码的情形很多
通常验证码是为了阻止自动化程序过于频繁访问一个网站,所以,出现的验证码可能会很难辨认,连人眼辨认都很困难,自动程序识别验证码就更困难了。
在数据采集过程中,如果不能及时输入验证码,或者输入了错误的验证码,就会致使网页无法显示,数据抓取也会中断,这也加大了自动化持续采集数据的难度。集搜客GooSeeker网络爬虫从多个方面应对验证码:
一旦遇到验证码、或者在自动登录时必须输入验证码的情形,集搜客GooSeeker网络爬虫与互联网打码平台对接,实时完成验证码输入。因为打码平台聚合了海量的打码人群,既能满足实时性要求,又能达到自动识别无法实现的精度。有效防止数据抓取中断,无需人工看管。
集搜客GooSeeker网页抓取软件可以设置定时自动采集,完全无需人工干预,自动采集最新数据,自动实现持续增量数据采集。比如
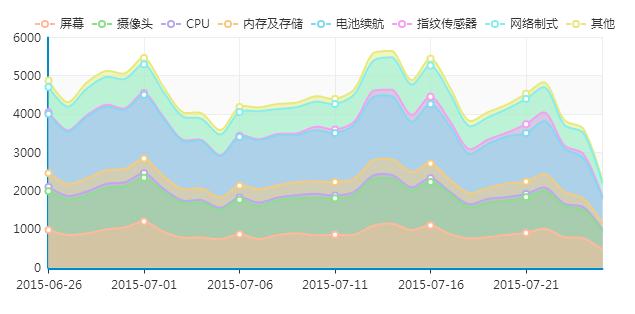
上图是手机消费者洞察系统中的一个截图,为了研究消费者品牌认知和态度,需要从互联网上采集所有用户评论信息,而且每天定时自动启动网络爬虫运行多次,把最新内容增量采集下来。
想要A网站、B网站、C网站……等等多个网站一起采集怎么办?
多个任务,快速采集,高效作业,让您的工作变得轻松愉快。
大数据时代,就是海量信息时代,我们有时候需要的数据量非常多,然而受到个人电脑的性能和网速的限制,数据获取者常常在数据获取方面耗费大量的时间和精力。所以当您的采集任务过于繁重时,您可以借助您的小伙伴的电脑,让多台电脑同时为您的采集任务服务,如果您一时没办法找到足够的帮助资源,可以来我们的社区,向其他小伙伴寻求帮助;集搜客的并行抓取功能,一方面可以帮助个人解决效率低下的问题,另一方面也促进社区闲散资源的整合利用;所以请加入我们的集搜客社区,快速寻求支援,既可以将自己的闲散资源进行有效的商业转化,也是增进收入的另一种选择。

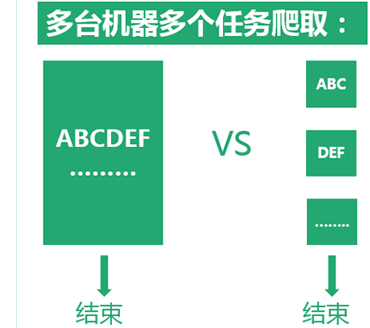
对于百万、千万甚至更大的的网页抓取量,可选择 分布式采集的方式,把采集任务分配到多台电脑上执行,这需要在集搜客会员中心创建工作组,启动会员互助抓取。但如果抓取量不那么大,或者即便启动多机并行抓取,也希望在一台计算机上并行运行多个爬虫程序,从而充分利用计算机的能力,这就可以用到集搜客新增的“集搜”功能。
“集搜”功能能够支持同一台电脑手工启动并行运行多个爬虫窗口,无需编程,只需在DS打数机的操作界面的 抓取规则列表上点击“集搜”按钮,就能为该规则启动一个爬虫窗口。如果列表一共罗列了20个抓取规则,则可以同时运行20个爬虫窗口。
集搜客网络爬虫还可以 自动启动定时抓取任务,同样也可以启动多个并行抓取窗口,达到相同的目的。但是,集搜功能是一键点击手工启动的,免除编写自启动指令文件,更加便捷。
相对于其它网页抓取软件提供的云采集服务,虽然云采集号称并行利用云中的众多服务器,理论上能够达到同样的目的,但是在云中运行的任务无法实时掌控他们的运行状态,假设需要实时比价或者负面口碑或者危机跟踪,时间过去了才发现没有抓全,再补救就来不及了。另外,云资源需要排队等待,时间不可控,无法用于时效性要求高的场合,当然,云资源付费使用也是不得不面对的问题。
爬虫不仅可以抓取PC网站上的数据,还可以抓取手机网站上的数据。移动互联网强势崛起后,人们通过手机访问互联网的频率越来越高,同一个目标网站,移动端和PC端显示的内容是不一样的,有区别的场景举例如下:
使用GooSeeker采集手机网站数据和采用PC网站数据同样简单, 可视化定义抓取规则的过程完全一样。
为了告知目标网站目前使用手机端(模拟的),需要设置agent类型,从而网络爬虫使用指定类型的agent访问网站,使PC端看到移动端的网页内容。这样就能用同一个集搜客网页抓取程序获得手机站内容。
(请注意:这个功能并不涉及手机APP的内容抓取,抓取的内容仍然来自于网页,是适合手机屏幕大小网页。)
联系人:华天清
联系电话:0755-83180322
联系地址:广东省深圳市南山区 深圳市南山区招商街道蛇口南海大道1079号花园城数码大厦B座202,203号




 8 年
8 年












